I am joining a new project about language models and my primary focus is on constructing parallel corpora across languages.
Multilingual LLM
Multilingual Capability of LLM
ChatGPT is not a perfect multilingual model
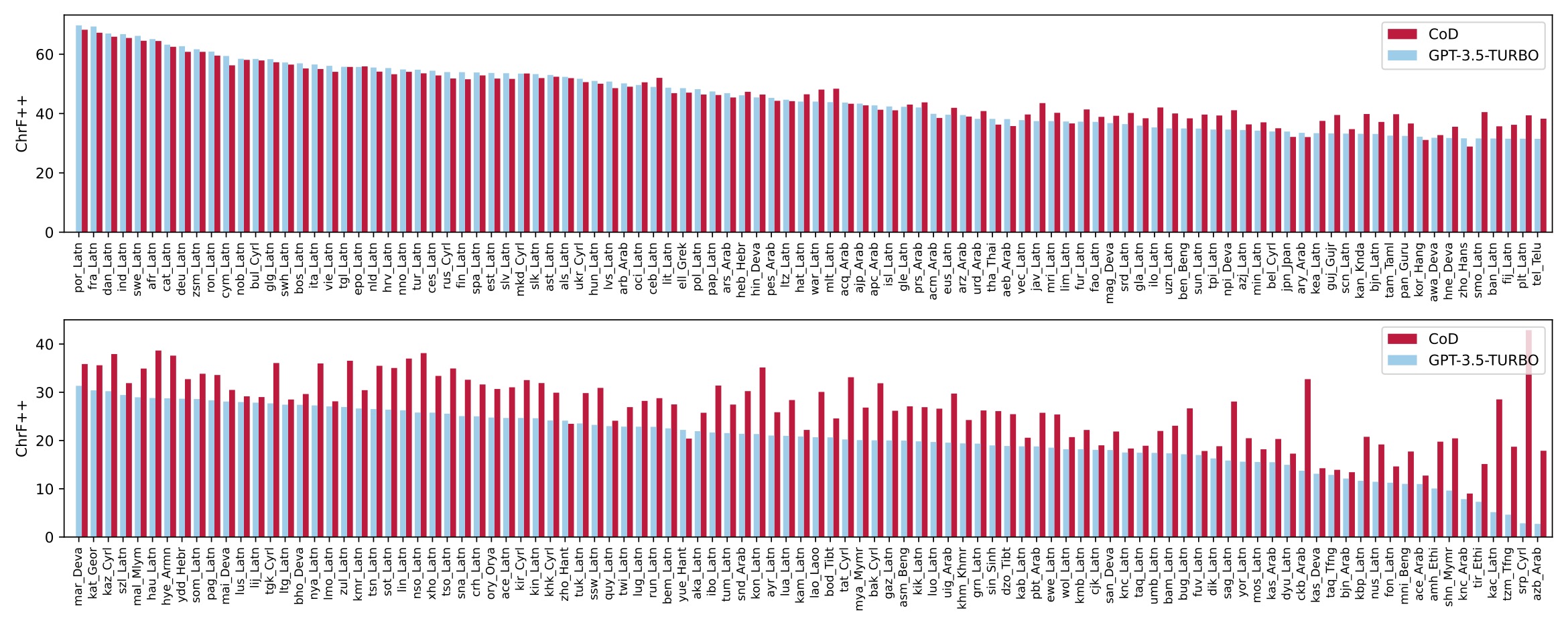
Illustrated comparison of 200 languages translated from English into various target languages, sorted by their language scores in ChrF++ for ChatGPT. Source: (Lu et al. 2023)
Related Work
As I progress with this project, I am documenting noteworthy related works for future references.
No Language Left Behind @ Meta AI (2023) Project Page
| arxiv paper
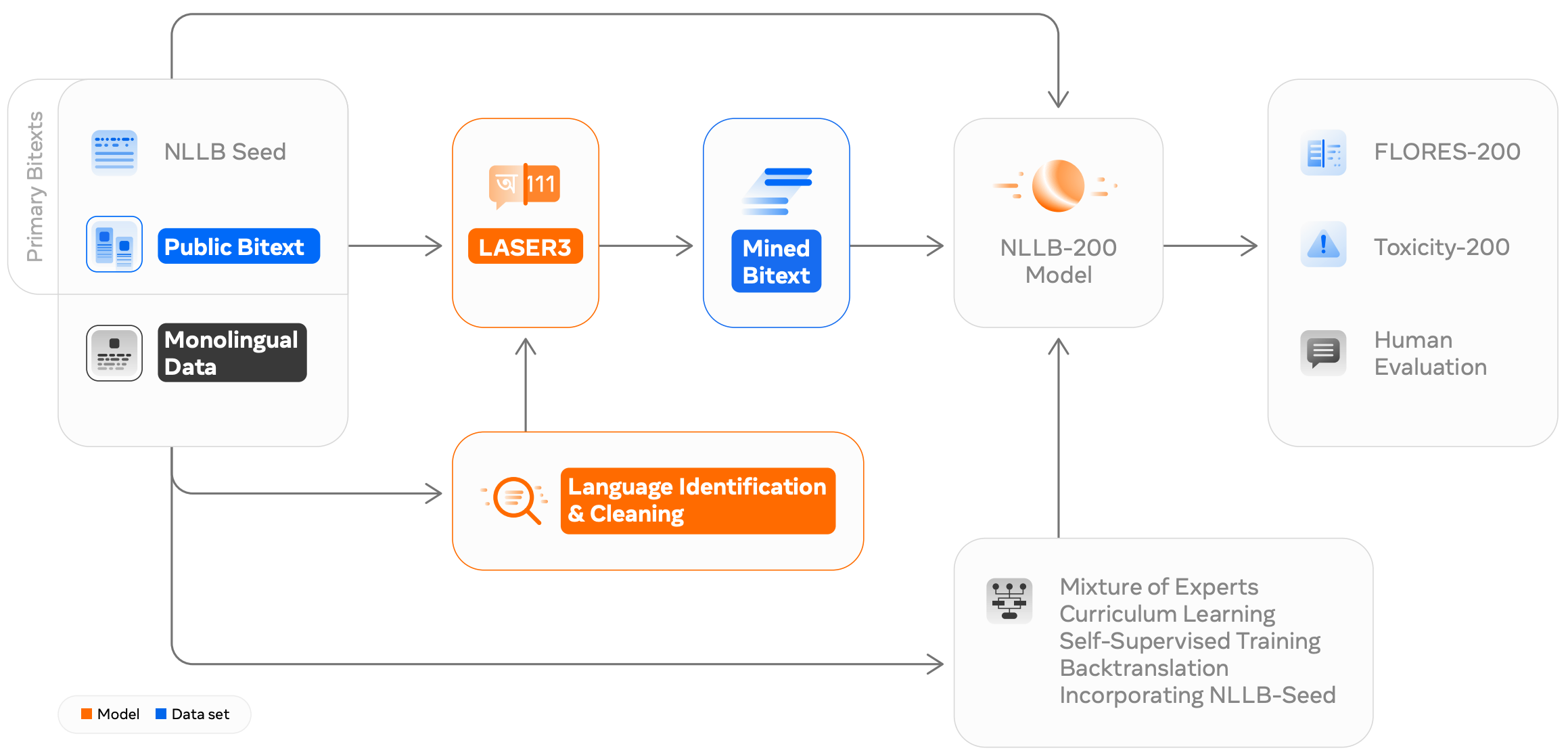
| Fairseq-NLLB Languages Involved: 200 languages Pipeline (Automatical Dataset Construction): Train language identification systems (LID) to label the text -> Gather and Clean non-aligned Monolingual Data at Scale (crawl, apply language identification, clean with heuristics, deduplicate, filter with Language Model Filtering) -> Bitext Mining, especially for Low-Resource Languages.NLLB creates translation training data for hundreds of languages automatically.
The core idea behind is to expand existing datasets: collecting non-aligned monolingual data and utilizing large-scale data mining (Schwenk et al., 2021b) to identify sentences with a high likelihood of being translations of one another in different languages.
Automatic Dataset Creation Contributions of No Language Left Behind.
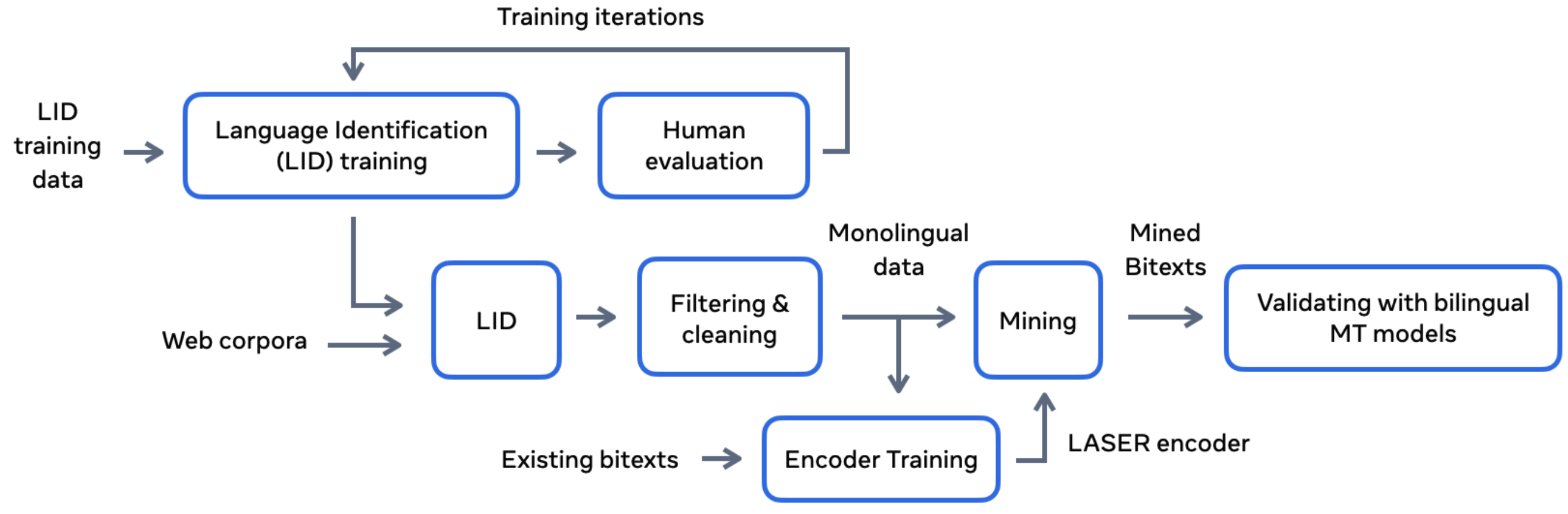
Train Language Identification (LID) Systems:
Utilize fasttext for character-level n-gram embeddings from input text.
A multiclass classifier with softmax is empirically better than multiple binary classifiers for LID tasks.
Temperature upsampling for underrepresented languages: sentences from a language $l$ representing $p_l$ percent of the dataset are sampled proportionally to $p_l^{\frac{1}{T}}$. Optimal performance was obtained at $\frac{1}{T}=0.3$.
Improving LID with linguistic analysis.
Data Collection and Cleaning:
Preprocessing data from CommonCrawl (CC) and ParaCrawl to remove markup and normalize encoding to UTF-8.
Truncating URLs and hashtags, applying LID to each web paragraph, and choosing a sentence splitter based on predicted language. Re-running LID after splitting and discarding sentences that do not match paragraph-level LID. Tuning LID detection thresholds using ParaCrawl’s monolingual data distribution.
Cleaning with heuristics, removing sentences that do not meet reasonable quality criteria for length, space/punctuation/number/emoji ratios, and repeated characters, while considering language-specific variations.
Performing global deduplication for each language.
Applying language model filtering on a few high-resource languages only, as it is difficult to train high-quality language models for low-resource languages. For English, use KenLM (Heafield, 2011) model from CCNet (Wenzek et al., 2020).
Bitext Mining (mainly focus on bitexts paired with English): The underlying idea is first learn a multilingual sentence embedding space and to use a similarity measure in that space to decide whether two sentences are parallel or not.
Overview of NLLB Bitext Mining Pipeline. Language identification is applied on web corpora to extract monolingual sentences. Aligned pairs are later identified with LASER3.
Construction Method of Parallel Corpus for Minority Language Machine Translation
Languages Involved: Persian, Hindi, Indonesian <-> Chinese Pipeline: Crawling Web Content in Minor Languages -> Translating with Human Translators -> Quality Inspection.Details
Source of Monolingual Corpus: Utilizing the Common Crawl Capture Index (CDX) to filter relevant URLs from the Common Crawl indexes.
Crawling the Monolingual Corpus: Using 5 seed URLs (The Khaama Press News Agency, TOLOnews, RadioAzadi, Pajhok, 1TVNews.af), it crawls recent content in Persian, Hindi, and Indonesian. Breadth-First Search (BFS) approach is used to gather all URLs under selected domain names. The data is then subjected to a series of steps: removing HTML tags, employing entity recognition tools to extract sentences, and preserving their original order.
Data cleaning involves:
a) Deduplication of sentences.
b) Filtering sentences to include only those with a length between 20 to 50 words.
c) Removing sentences containing less than 75% of the Unicode block of the target language.
d) Maintaining the order of sentences.
e) Implementing active learning techniques: rank and choose sentences based on information gain. However, this prioritizes sentences containing personal names, place names, and organization names.
Human Translation: Senior grade students from language majors are engaged to perform manual translation or adopt Machine Translation Post Editing (MTPE) techniques.
Quality Inspection is carried out through two main approaches:
a) Machine checks: Translations are compared with Google Translator outputs using editing-distance, Needleman-Wunsch algorithms, and n-gram precision to calculate the editing rate. If the editing rate is below 10%, re-translation is required.
b) Evaluation by a professional translation company.
Download:Project Page Dataset Statistics: 7500 human-annotated development and test examples in NLI three-way classification format in 15 languages, making a total of 112,500 annotated pairs. Languages Involved: English(en), French(fr), Spanish(es), German(de), Greek(el), Bulgarian(bg), Russian(ru), Turkish(tr), Arabic(ar), Vietnamese(vi), Thai(th), Chinese(zh), Hindi(hi), Swahili(sw), Urdu(ur) Pipeline: Collect English corpus -> Generate three hypotheses for each premise (one for each possible label) using crowdsourcing platform -> Translate resulting sentences into 15 languages.Details
XNLI corpus is designed to evaluate cross-lingual sentence understanding, where models have to be trained in one language and tested in different ones.
Data Collection:
Collect the English corpus involves following the same procedure as the MultiNLI corpus: 250 sentences are sampled from each of the ten sources, with nine from the second release of the Open American National Corpus: Face-To-Face, Telephone, Government, 9/11, Letters, Oxford University Press (OUP), Slate, Verbatim, and Government. The tenth source, Fiction, is drawn from the novel Captain Blood (Sabatini, 1922). For more details on each genre, refer to (Williams et al. 2017).
Produce three hypotheses for each premise, one for each possible label, by tasking the same MultiNLI worker pool from a crowdsourcing platform.
Translate the resulting sentences into 15 languages is done by translators via the One Hour Translation platform. Premises and hypotheses are translated separately, to ensure that no context is added to the hypothesis that was not there originally.
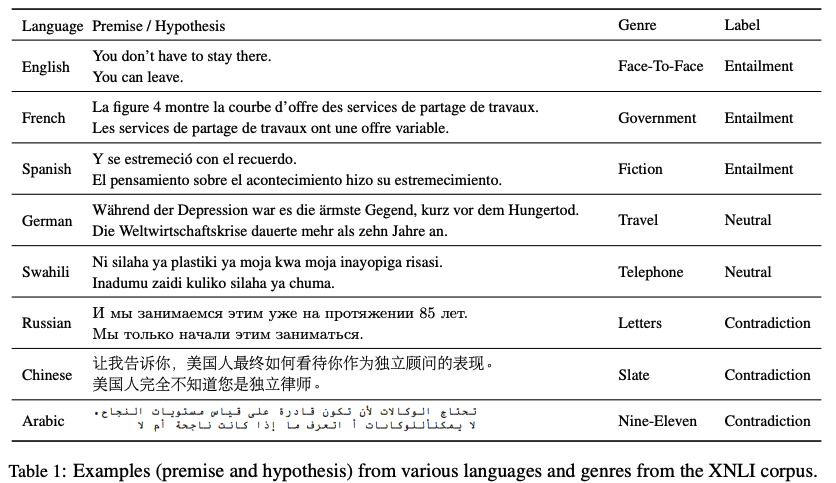
Data Example:
In natural language inference (NLI), also known as recognizing textual entailment (RTE), a system is tasked with reading two sentences and determining whether one entails the other, contradicts it, or neither (neutral).
ChrF (Character N-gram F-score) is a metric that measures the similarity between the reference (ground truth) and the machine-generated translation, by counting matching character n-grams (sequences of n characters). Let $R$ be the set of character n-grams in the reference, and $T$ be the set of character n-grams in the translation. Then, the precision
$P_{ChrF}$ and recall $R_{ChrF}$ for ChrF are given by:
\[
\text{P}_{\text{ChrF}} = \frac{\text{Number of matching character n-grams between R and T}}{\text{Number of character n-grams in T}} \\
\text{R}_{\text{ChrF}} = \frac{\text{Number of matching character n-grams between R and T}}{\text{Number of character n-grams in R}}
\]
The F-score $F_{ChrF}$ is then calculated as the harmonic mean of precision and recall:
ChrF++ is an enhanced version of ChrF that addresses some of the limitations of the original metric. Let $len_R$ be the total number of characters in the reference, and $len_T$ be the total number of characters in the translation. The ChrF++ is calculated as follows:
\[
\text{P}_{\text{ChrF++}} = \frac{\text{Number of matching character n-grams between R and T}}{\text{len}_{\text{T}}} \\
\text{R}_{\text{ChrF++}} = \frac{\text{Number of matching character n-grams between R and T}}{\text{len}_{\text{R}}} \\
\text{F}_{\text{ChrF++}} = \frac{2 \times \text{P}_{\text{ChrF++}} \times \text{R}_{\text{ChrF++}}}{\text{P}_{\text{ChrF++}} + \text{R}_{\text{ChrF++}}}
\]