Preliminaries: Low-Rank Adaption (LoRA)
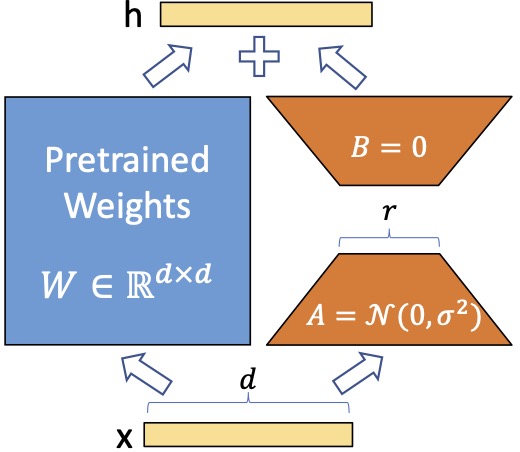
we only train A and B.
LoRA (Hu et al. 2021) is a commonly used technique to deal with the problem of fine-tuning large-language models.
LoRA freezes the pre-trained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, greatly reducing the number of trainable parameters for downstream tasks. This vastly reduces the storage requirement for large language models adapted to specific tasks and enables efficient task-switching during deployment all without introducing inference latency.
Motivation
It is commonplace to utilize foundation models that have undergone pre-training on extensive datasets. These models possess pre-existing knowledge and are typically more adept at mastering unseen, yet similar tasks. This allows us to leverage the knowledge gained by a pre-trained model and adapt it to a specific task or dataset with relatively less training data. This process, known as fine-tuning, involves taking a pre-trained model and further training it on a specific task or dataset to enhance its performance in that particular domain.
How does fine-tuning work?1
Classical fine-tuing. During the fine-tuning process, the pre-trained model is presented with input from the new task-specific dataset.
It then generates predictions and compares them with the ground truth. Through iterative adjustments to the model’s weights, as illustrated in Fig 2.a, the model refines its predictions. Repeating this process over multiple iterations allows the pre-trained model to become fine-tuned for the downstream task.
As larger models are trained every few months, fine-tuning becomes a critical challenge due to the exponential increase in the size of pre-trained models (such as GPT-3 with ~175 Billion parameters).
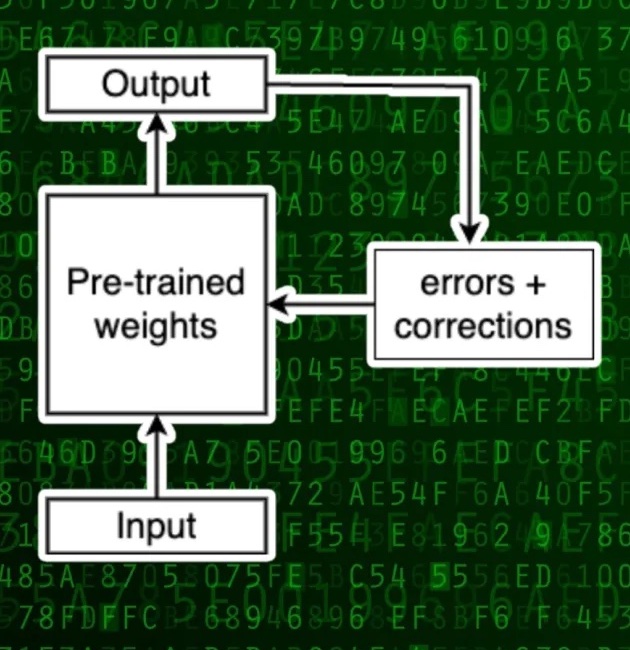
fine-tuning
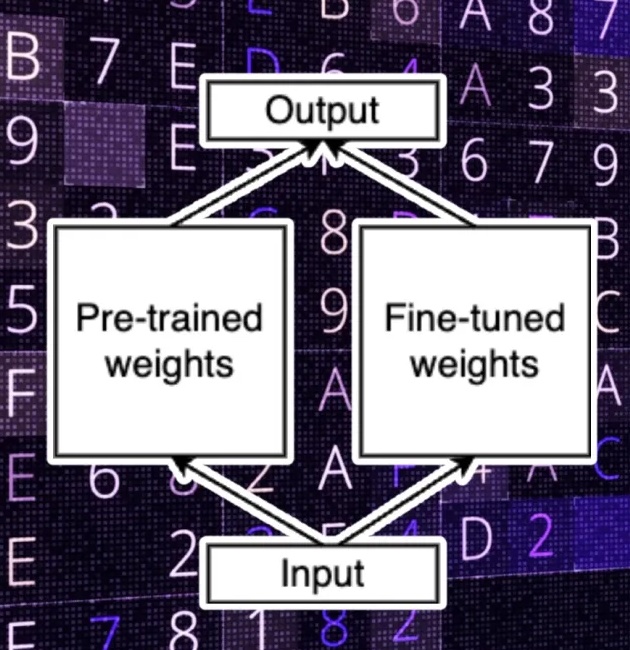
Adapter tuing. Later, there is a new technique for the fine-tuning process, depicted in Fig 2.b. In this new method, we freeze the original weights of the model and refrain from modifying them during the fine-tuning process. Instead, we introduce a separate set of weights where we apply the necessary modifications. We refer to these two sets as the “pre-trained” and “fine-tuned” weights, respectively.
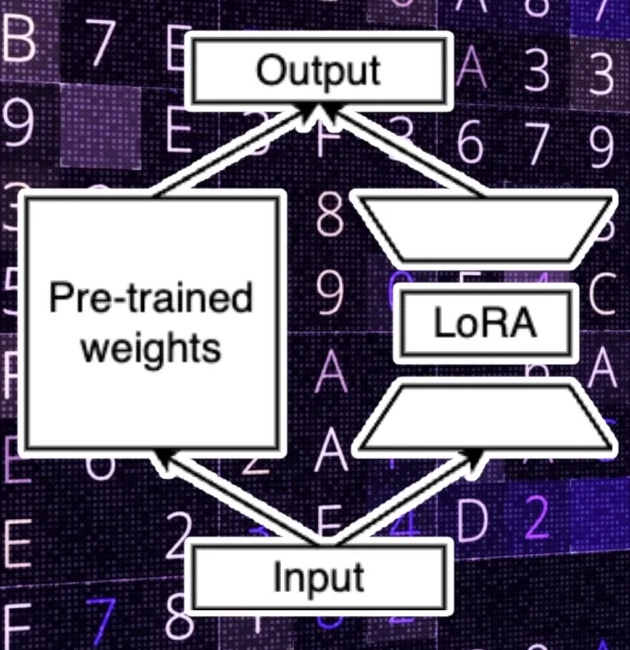
LoRA. Furthermore, LoRA, as shown in Fig 2.c, suggests that the full-rank weight matrix is not necessary when fine-tuning a large model for a downstream task. We can actually reduce the dimension of the downstream parameters while preserving most of the learning capacity of the model. This concept is inspired (Li et al. 2018) and (Aghajanyan et al. 2020), which show that the learned over-parametrized models in fact reside on a low intrinsic dimension.
In essence, LoRA uses two downstream weight matrices: one to transform the input parameters from the original dimension to the low-rank dimension, and another to transform the low-rank data to match the output dimensions of the original model.
During training, modifications are made to the LoRA parameters, which are significantly fewer than the original weights (hence allowing faster training and reduces the cost compared to full fine-tuning).
At inference time, the output of LoRA is added to the pre-trained parameters to calculate the final values.
Understanding LoRA
Problem statement: Suppose we are given a pre-trained model $P_{\Phi}(y|x)$ parametrized by $\Phi$. Each downstream task is represented by a training dataset of context-target pairs: $Z= \lbrace (x_i, y_i)\rbrace_{i=1,\dots,N}$.
During full fine-tuning, the model is initialized to pre-trained weights $\Phi_0$ and updated to $\Phi_0 + \Delta\Phi$ by repeatedly following the gradient to optimize the downstream task objectives.
Rank Deficiency. The core assumption of LoRA, inspired by (Aghajanyan et al. 2020), is that the change in weights during model adaptation reside on a low intrinsic dimension (rank).
For a pre-trained weight matrix $W_0 \in \mathbb{R}^{d \times k}$, we constrain its update by representing the latter with a low-rank decomposition $W_0 + \Delta W = W_0 + BA$, where $B ∈ \mathbb{R}^{d\times r}$, $A ∈ \mathbb{R}^{r\times k}$, and the rank $r \ll \min(d, k)$.
During training, $W_0$ is frozen and does not receive gradient updates, while A and B contain trainable parameters.
Training setup: LoRA modifies the output of forward pass into $h = W_0x + \Delta Wx = W_0x + BAx$.
The initial LoRA paper uses a random Gaussian initialization for A and zero for B, so $\Delta W = BA$ is zero at the beginning of training.
It then scales $\Delta Wx$ by $\frac{\alpha}{r}$, where $\alpha$ is a constant in $r$. When optimizing with Adam, tuning α is roughly the same as tuning the learning rate if we scale the initialization appropriately. As a result, the paper simply sets $\alpha$ to the first $r$ it tried and does not tune it.
This scaling helps to reduce the need to retune hyperparameters when we vary $r$ (Yang & Hu, 2021)
Pros
- Improved efficiency and reduced training cost: By reducing the rank of the model’s weight matrices, LoRA makes model adaptation significantly more parameter- and compute-efficient. It can lower the hardware barrier to entry by up to 3 times when using adaptive optimizers.
- Retains performance: No Additional Inference Latency. Thanks to the linear design, when deployed in production, we can explicitly compute and store $W = W_0 + BA$ and perform inference as usual. When we want to switch tasks, we can simply recover $W_0$ by subtracting $BA$ and then adding a different $B’A’$.
- Easier customization: Pre-trained model can be shared and used to build many small LoRA modules for different tasks. We can freeze the shared model and efficiently switch tasks by replacing the matrices A and B in Fig 1, reducing the storage requirement and task-switching overhead significantly.
- LoRA is agnostic to training objective and orthogonal to many prior methods and can be combined with many of them, such as prefix-tuning.
Cons
- Risk of losing information: By reducing the rank of the weight matrices, LoRA discards certain less significant features. However, community practice indicates that this is not a major concern in most cases.